import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV, ParameterGrid, KFold, StratifiedKFold
from sklearn.pipeline import Pipeline, FeatureUnion
import itertools
import concurrent.futures
from itertools import repeat
from sklearn.base import is_classifier
from sklearn.linear_model import LinearRegression
from sklearn.model_selection._split import check_cv
from sklearn.externals.joblib import Parallel, delayed
from sklearn.base import clone
from sklearn.model_selection._search import BaseSearchCV
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
The Elegance and Inefficiencies of GridSeaching a Pipeline
The Set Up/Problem
The idea for this comes from my growing habit of using pipelines to organize my data modeling process, as well as using it as a why to try out many different parameters and methodologies at once. Now this by it’s nature is a time intensive process as it is creating many thousands (based on how many parameters you are trying) of models, but I also realized that due to the way in which I format and search my pipelines, I was aggravating the problem.
To understand where the issue comes into play, I will illlustrate the framework I use for pipelines below.
- Pipeline
- Feature Union - This Feature Union holds pipelines for cleaning/transforming all the data I want to use for the model.
- Middle Steps - Whether this is scaling all the data, or a form of feature selection.
- Modeling - This is the final step of the pipeline where the data is given to the model to be used.
Insert Drawing Here
The issue here is in the Feauture Union. Since I like to use the pipeline to clean my data, I believe there is time lost as for every variation of a model that is tried the entire pipeline is running which means that the data, which has already been fit, is getting fit again everytime anyway. While this has most likely had trivial impact for my uses so far, using simple cleaning methods like mapping values, as I’ve moved into more intensive processes like Natural Languange Processing I think this becomes a much more significant time issue.
Now a simple solution would be to remove the Feature Union from the pipeline, fit it seperately, and then use the remaining pipeline for the gridsearch, however, that loses the ability to also easily GridSearch pieces of the data cleaning process.
So my goal is to confirm that the problem I think should exits truly has impact, and then implement my own estimator class as a wrapper for GridSearch to better optimize for my specific use case and pipeline format.
Sample Data
I will be using a consistent set of data to “Economic News” data to run these tests. I will not do a Train-Test split because I really don’t care about the actual results of the model here, just the tiem it takes to fit.
df = pd.read_csv('sample_data/economic_news.csv', usecols=[7, 11, 14])
df.text = df.text.apply(lambda x: x.replace('</br>', ''))
df.relevance = df.relevance.apply(lambda x: 1 if x == 'yes' else 0)
print(df.shape)
df.head()
(8000, 3)
| relevance | headline | text | |
|---|---|---|---|
| 0 | 1 | Yields on CDs Fell in the Latest Week | NEW YORK -- Yields on most certificates of dep... |
| 1 | 0 | The Morning Brief: White House Seeks to Limit ... | The Wall Street Journal OnlineThe Morning Brie... |
| 2 | 0 | Banking Bill Negotiators Set Compromise --- Pl... | WASHINGTON -- In an effort to achieve banking ... |
| 3 | 0 | Manager's Journal: Sniffing Out Drug Abusers I... | The statistics on the enormous costs of employ... |
| 4 | 1 | Currency Trading: Dollar Remains in Tight Rang... | NEW YORK -- Indecision marked the dollar's ton... |
Proving the Problem
In this section I will look at the amount of time it takes for a few types of data cleaning/transofrmation of different complexities, and how they scale on their own and within GridSearches in order to see how much time constantly refitting data is costing.
#set up some stuff
#of times to GridSearch something
reps = [1,5,10,25,50,75,100,150,200,250,500,750,1000,2500,5000]
tmp = []
df['nums'] = df.index
rs = 779
np.random.seed(rs)
df.nums = df.nums.apply(lambda x: 100*x* np.random.rand())
df.head()
| relevance | headline | text | nums | |
|---|---|---|---|---|
| 0 | 1 | Yields on CDs Fell in the Latest Week | NEW YORK -- Yields on most certificates of dep... | 0.000000 |
| 1 | 0 | The Morning Brief: White House Seeks to Limit ... | The Wall Street Journal OnlineThe Morning Brie... | 72.259737 |
| 2 | 0 | Banking Bill Negotiators Set Compromise --- Pl... | WASHINGTON -- In an effort to achieve banking ... | 184.913663 |
| 3 | 0 | Manager's Journal: Sniffing Out Drug Abusers I... | The statistics on the enormous costs of employ... | 94.107106 |
| 4 | 1 | Currency Trading: Dollar Remains in Tight Rang... | NEW YORK -- Indecision marked the dollar's ton... | 336.160412 |
eff_orig = pd.DataFrame(reps, columns=['reps'])
eff_orig['fits'] = eff_orig.reps.apply(lambda x: x*2)
eff_orig
| reps | fits | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 5 | 10 |
| 2 | 10 | 20 |
| 3 | 25 | 50 |
| 4 | 50 | 100 |
| 5 | 75 | 150 |
| 6 | 100 | 200 |
| 7 | 150 | 300 |
| 8 | 200 | 400 |
| 9 | 250 | 500 |
| 10 | 500 | 1000 |
| 11 | 750 | 1500 |
| 12 | 1000 | 2000 |
| 13 | 2500 | 5000 |
| 14 | 5000 | 10000 |
eff_cached = eff_orig.copy()
eff_ss = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', StandardScaler())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.nums.values.reshape(-1,1), df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_ss.append(diff.total_seconds())
eff_orig['ss_orig'] = eff_ss
eff_pf = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', PolynomialFeatures())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.nums.values.reshape(-1,1), df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_pf.append(diff.total_seconds())
eff_orig['pf_orig'] = eff_pf
eff_cv = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', CountVectorizer())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_cv.append(diff.total_seconds())
eff_orig['cv_orig'] = eff_cv
eff_tv = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', TfidfVectorizer())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_tv.append(diff.total_seconds())
eff_orig['tv_orig'] = eff_tv
eff_cv_td = []
for x in reps:
#setup
fu = FeatureUnion([
('text', Pipeline([
('pre-process', CountVectorizer()),
('truncate', TruncatedSVD(n_components=1, random_state=rs))
]))
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_cv_td.append(diff.total_seconds())
eff_orig['cv_td_orig'] = eff_cv_td
eff_tv_td = []
for x in reps:
#setup
fu = FeatureUnion([
('text', Pipeline([
('pre-process', TfidfVectorizer()),
('truncate', TruncatedSVD(n_components=1, random_state=rs))
]))
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_tv_td.append(diff.total_seconds())
eff_orig['tv_td_orig'] = eff_tv_td
Save Eff table to csv so no need to rerun
eff_orig
| reps | fits | ss_orig | pf_orig | cv_orig | tv_orig | cv_td_orig | tv_td_orig | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 0.225094 | 0.210267 | 6.232115 | 4.133495 | 4.286770 | 4.524483 |
| 1 | 5 | 10 | 0.194651 | 0.201753 | 11.817011 | 8.571318 | 8.815194 | 9.548219 |
| 2 | 10 | 20 | 0.207121 | 0.206395 | 18.046697 | 13.498752 | 13.731576 | 15.187596 |
| 3 | 25 | 50 | 0.310750 | 0.312342 | 39.263028 | 31.436065 | 31.830212 | 32.558791 |
| 4 | 50 | 100 | 0.424310 | 0.407476 | 73.355245 | 58.983665 | 59.402505 | 60.533114 |
| 5 | 75 | 150 | 0.521270 | 0.522610 | 106.176211 | 86.964126 | 88.038196 | 89.465739 |
| 6 | 100 | 200 | 0.527857 | 0.547297 | 139.342304 | 115.449600 | 116.504539 | 118.238184 |
| 7 | 150 | 300 | 0.715433 | 0.746119 | 207.939189 | 172.870768 | 174.088018 | 175.437701 |
| 8 | 200 | 400 | 0.841306 | 0.806791 | 274.387210 | 228.160459 | 230.957761 | 233.329937 |
| 9 | 250 | 500 | 0.994794 | 0.991691 | 341.709382 | 285.126249 | 288.773181 | 292.719185 |
| 10 | 500 | 1000 | 1.674138 | 1.710237 | 678.446888 | 568.165274 | 573.782917 | 579.152579 |
| 11 | 750 | 1500 | 2.371095 | 2.430035 | 1014.473684 | 851.777699 | 861.632572 | 865.554674 |
| 12 | 1000 | 2000 | 3.139456 | 3.147182 | 1352.139445 | 1134.881215 | 1146.537355 | 1154.976613 |
| 13 | 2500 | 5000 | 7.991735 | 8.531802 | 3367.759985 | 2829.689819 | 2864.428314 | 2883.357771 |
| 14 | 5000 | 10000 | 16.730484 | 15.057567 | 6756.219261 | 5671.877889 | 5720.519433 | 5791.198268 |
eff_orig.to_csv('efficiencyDForig.csv', index=False)
Try with Pipeline Memory Caching
from tempfile import mkdtemp
from sklearn.externals.joblib import Memory
cachedir = mkdtemp()
eff_ss = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', StandardScaler())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
], memory=Memory(cachedir=cachedir, verbose=0))
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.nums.values.reshape(-1,1), df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_ss.append(diff.total_seconds())
eff_cached['ss_cached'] = eff_ss
eff_pf = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', PolynomialFeatures())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
], memory=Memory(cachedir=cachedir, verbose=0))
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.nums.values.reshape(-1,1), df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_pf.append(diff.total_seconds())
eff_cached['pf_cached'] = eff_pf
eff_cv = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', CountVectorizer())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
], memory=Memory(cachedir=cachedir, verbose=0))
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_cv.append(diff.total_seconds())
eff_cached['cv_cached'] = eff_cv
eff_tv = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', TfidfVectorizer())
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
], memory=Memory(cachedir=cachedir, verbose=0))
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_tv.append(diff.total_seconds())
eff_cached['tv_cached'] = eff_tv
eff_cv_td = []http://localhost:8888/notebooks/PipelineEfficiency.ipynb#
for x in reps:
#setup
fu = FeatureUnion([
('text', Pipeline([
('pre-process', CountVectorizer()),
('truncate', TruncatedSVD(n_components=1, random_state=rs))
]))
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
], memory=Memory(cachedir=cachedir, verbose=0))
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_cv_td.append(diff.total_seconds())
eff_cached['cv_td_cached'] = eff_cv_td
eff_tv_td = []
for x in reps:
#setup
fu = FeatureUnion([
('text', Pipeline([
('pre-process', TfidfVectorizer()),
('truncate', TruncatedSVD(n_components=1, random_state=rs))
]))
])
pipe = Pipeline([
('fu', fu),
('model', LogisticRegression())
], memory=Memory(cachedir=cachedir, verbose=0))
params = {
'model__random_state':range(0,x)
}
gs = GridSearchCV(pipe, params, verbose=1, n_jobs=-1, cv=2)
#start timer
start = datetime.now()
gs.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_tv_td.append(diff.total_seconds())
eff_cached['tv_td_cached'] = eff_tv_td
eff_cached
| reps | fits | ss_cached | pf_cached | cv_cached | tv_cached | cv_td_cached | tv_td_cached | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 0.220370 | 0.213159 | 8.577361 | 6.538034 | 6.739061 | 6.718483 |
| 1 | 5 | 10 | 0.210165 | 0.217480 | 10.221625 | 7.189253 | 6.298098 | 6.342444 |
| 2 | 10 | 20 | 0.211886 | 0.215039 | 15.564601 | 11.348357 | 10.216127 | 10.532659 |
| 3 | 25 | 50 | 0.326096 | 0.325405 | 34.597346 | 26.822049 | 24.723027 | 25.100113 |
| 4 | 50 | 100 | 0.417474 | 0.424614 | 64.362823 | 50.839350 | 47.331228 | 48.007842 |
| 5 | 75 | 150 | 0.598978 | 0.532198 | 94.691714 | 75.714144 | 70.753043 | 71.175799 |
| 6 | 100 | 200 | 0.657977 | 0.604862 | 125.989611 | 100.350146 | 93.655833 | 94.807464 |
| 7 | 150 | 300 | 0.848278 | 0.831244 | 187.994630 | 150.029235 | 139.665444 | 141.309259 |
| 8 | 200 | 400 | 1.000400 | 1.069972 | 249.437291 | 199.660035 | 186.383742 | 188.557826 |
| 9 | 250 | 500 | 1.278369 | 1.291126 | 310.134293 | 249.871598 | 232.914126 | 235.549512 |
| 10 | 500 | 1000 | 2.243304 | 2.248786 | 616.757385 | 499.087750 | 464.231040 | 468.925885 |
| 11 | 750 | 1500 | 3.232118 | 3.320747 | 919.324976 | 745.893859 | 696.744014 | 702.962536 |
| 12 | 1000 | 2000 | 4.202490 | 4.257102 | 1233.318759 | 992.546725 | 932.418590 | 937.363592 |
| 13 | 2500 | 5000 | 10.107030 | 10.359197 | 3063.400708 | 2481.567094 | 2326.713119 | 2337.549000 |
| 14 | 5000 | 10000 | 19.715110 | 20.546900 | 6141.560259 | 4969.542471 | 4642.505104 | 4678.323244 |
eff_cached.to_csv('efficiencyDFcached.csv', index=False)
Visualize Times
eff_orig = pd.read_csv('efficiencyDForig.csv')
eff_orig
| reps | fits | ss_orig | pf_orig | cv_orig | tv_orig | cv_td_orig | tv_td_orig | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 0.225094 | 0.210267 | 6.232115 | 4.133495 | 4.286770 | 4.524483 |
| 1 | 5 | 10 | 0.194651 | 0.201753 | 11.817011 | 8.571318 | 8.815194 | 9.548219 |
| 2 | 10 | 20 | 0.207121 | 0.206395 | 18.046697 | 13.498752 | 13.731576 | 15.187596 |
| 3 | 25 | 50 | 0.310750 | 0.312342 | 39.263028 | 31.436065 | 31.830212 | 32.558791 |
| 4 | 50 | 100 | 0.424310 | 0.407476 | 73.355245 | 58.983665 | 59.402505 | 60.533114 |
| 5 | 75 | 150 | 0.521270 | 0.522610 | 106.176211 | 86.964126 | 88.038196 | 89.465739 |
| 6 | 100 | 200 | 0.527857 | 0.547297 | 139.342304 | 115.449600 | 116.504539 | 118.238184 |
| 7 | 150 | 300 | 0.715433 | 0.746119 | 207.939189 | 172.870768 | 174.088018 | 175.437701 |
| 8 | 200 | 400 | 0.841306 | 0.806791 | 274.387210 | 228.160459 | 230.957761 | 233.329937 |
| 9 | 250 | 500 | 0.994794 | 0.991691 | 341.709382 | 285.126249 | 288.773181 | 292.719185 |
| 10 | 500 | 1000 | 1.674138 | 1.710237 | 678.446888 | 568.165274 | 573.782917 | 579.152579 |
| 11 | 750 | 1500 | 2.371095 | 2.430035 | 1014.473684 | 851.777699 | 861.632572 | 865.554674 |
| 12 | 1000 | 2000 | 3.139456 | 3.147182 | 1352.139445 | 1134.881215 | 1146.537355 | 1154.976613 |
| 13 | 2500 | 5000 | 7.991735 | 8.531802 | 3367.759985 | 2829.689819 | 2864.428314 | 2883.357771 |
| 14 | 5000 | 10000 | 16.730484 | 15.057567 | 6756.219261 | 5671.877889 | 5720.519433 | 5791.198268 |
eff_cached = pd.read_csv('efficiencyDFcached.csv')
eff_cached
| reps | fits | ss_cached | pf_cached | cv_cached | tv_cached | cv_td_cached | tv_td_cached | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 0.220370 | 0.213159 | 8.577361 | 6.538034 | 6.739061 | 6.718483 |
| 1 | 5 | 10 | 0.210165 | 0.217480 | 10.221625 | 7.189253 | 6.298098 | 6.342444 |
| 2 | 10 | 20 | 0.211886 | 0.215039 | 15.564601 | 11.348357 | 10.216127 | 10.532659 |
| 3 | 25 | 50 | 0.326096 | 0.325405 | 34.597346 | 26.822049 | 24.723027 | 25.100113 |
| 4 | 50 | 100 | 0.417474 | 0.424614 | 64.362823 | 50.839350 | 47.331228 | 48.007842 |
| 5 | 75 | 150 | 0.598978 | 0.532198 | 94.691714 | 75.714144 | 70.753043 | 71.175799 |
| 6 | 100 | 200 | 0.657977 | 0.604862 | 125.989611 | 100.350146 | 93.655833 | 94.807464 |
| 7 | 150 | 300 | 0.848278 | 0.831244 | 187.994630 | 150.029235 | 139.665444 | 141.309259 |
| 8 | 200 | 400 | 1.000400 | 1.069972 | 249.437291 | 199.660035 | 186.383742 | 188.557826 |
| 9 | 250 | 500 | 1.278369 | 1.291126 | 310.134293 | 249.871598 | 232.914126 | 235.549512 |
| 10 | 500 | 1000 | 2.243304 | 2.248786 | 616.757385 | 499.087750 | 464.231040 | 468.925885 |
| 11 | 750 | 1500 | 3.232118 | 3.320747 | 919.324976 | 745.893859 | 696.744014 | 702.962536 |
| 12 | 1000 | 2000 | 4.202490 | 4.257102 | 1233.318759 | 992.546725 | 932.418590 | 937.363592 |
| 13 | 2500 | 5000 | 10.107030 | 10.359197 | 3063.400708 | 2481.567094 | 2326.713119 | 2337.549000 |
| 14 | 5000 | 10000 | 19.715110 | 20.546900 | 6141.560259 | 4969.542471 | 4642.505104 | 4678.323244 |
fig, ax = plt.subplots(figsize=(16,8))
plt.plot(eff_orig['fits'], eff_orig['ss_orig'],
lw=3, color='red', label='Standard Scaler Original')
plt.plot(eff_orig['fits'], eff_orig['pf_orig'],
lw=3, color='red', linestyle='--', label='Polynomial Feature Original')
plt.plot(eff_orig['fits'], eff_orig['cv_orig'],
lw=3, color='red', linestyle='-.', label='Count Vectorizer Original')
plt.plot(eff_orig['fits'], eff_orig['tv_orig'],
lw=3, color='red', linestyle=':', label='TfidVectorizer Original')
plt.plot(eff_cached['fits'], eff_cached['ss_cached'],
lw=3, color='blue', label='Standard Scaler Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['pf_cached'],
lw=3, color='blue', linestyle='--', label='Polynomial Feature Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['cv_cached'],
lw=3, color='blue', linestyle='-.', label='Count Vectorizer Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['tv_cached'],
lw=3, color='blue', linestyle=':', label='TfidVectorizer Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Pipelines")
plt.legend(loc = 'best')
plt.show()
fig, ax = plt.subplots(figsize=(16,8))
plt.plot(eff_orig['fits'], eff_orig['ss_orig'],
lw=3, color='red', label='Standard Scaler Original')
plt.plot(eff_orig['fits'], eff_orig['pf_orig'],
lw=3, color='red', linestyle='--', label='Polynomial Feature Original')
plt.plot(eff_cached['fits'], eff_cached['ss_cached'],
lw=3, color='blue', label='Standard Scaler Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['pf_cached'],
lw=3, color='blue', linestyle='--', label='Polynomial Feature Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Pipelines")
plt.legend(loc = 'best')
plt.show()
fig, ax = plt.subplots(figsize=(16,8))
plt.plot(eff_orig['fits'], eff_orig['cv_orig'],
lw=3, color='red', linestyle='-', label='Count Vectorizer Original')
plt.plot(eff_orig['fits'], eff_orig['tv_orig'],
lw=3, color='red', linestyle='--', label='TfidVectorizer Original')
plt.plot(eff_cached['fits'], eff_cached['cv_cached'],
lw=3, color='blue', linestyle='-', label='Count Vectorizer Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['tv_cached'],
lw=3, color='blue', linestyle='--', label='TfidVectorizer Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Pipelines")
plt.legend(loc = 'best')
plt.show()
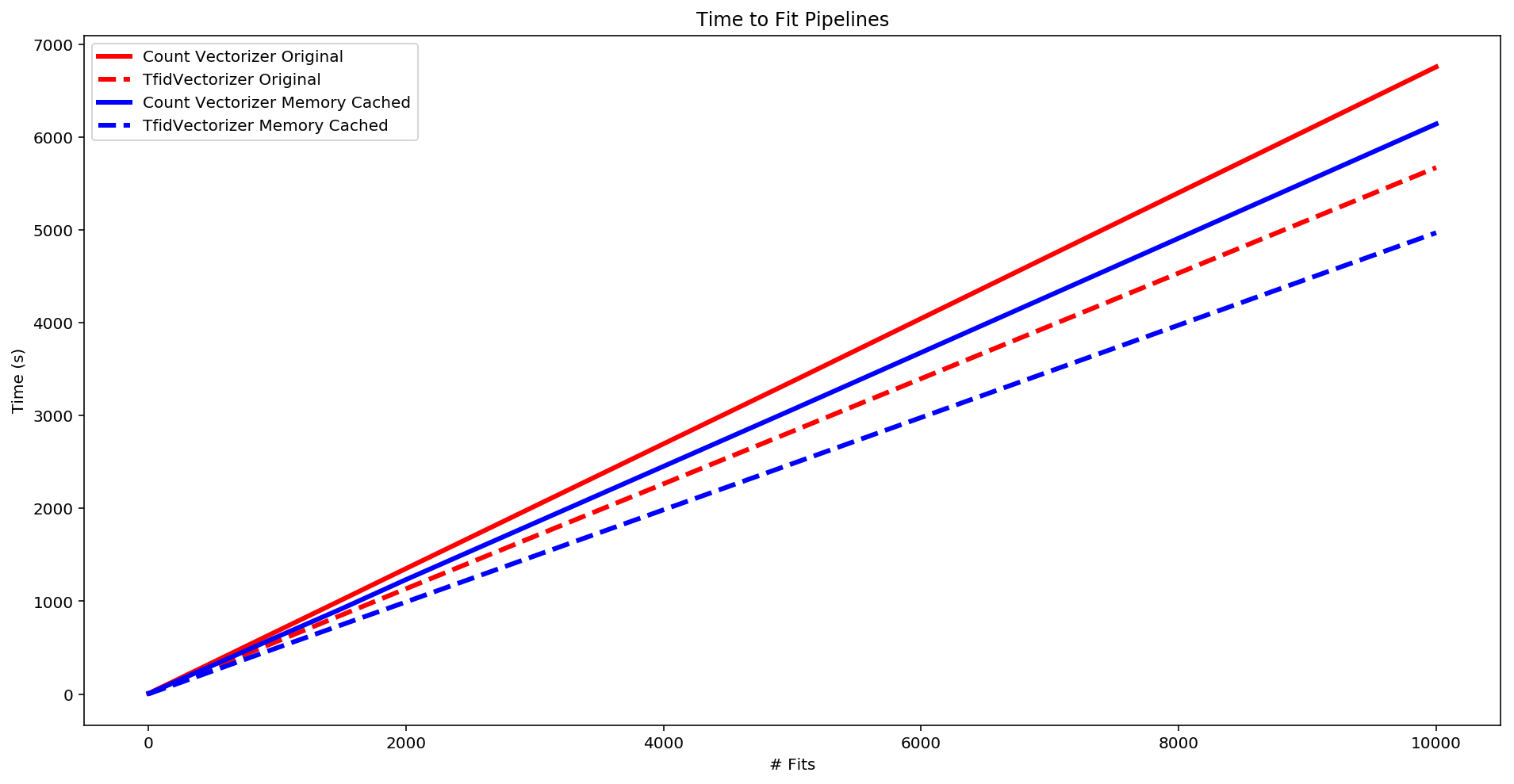
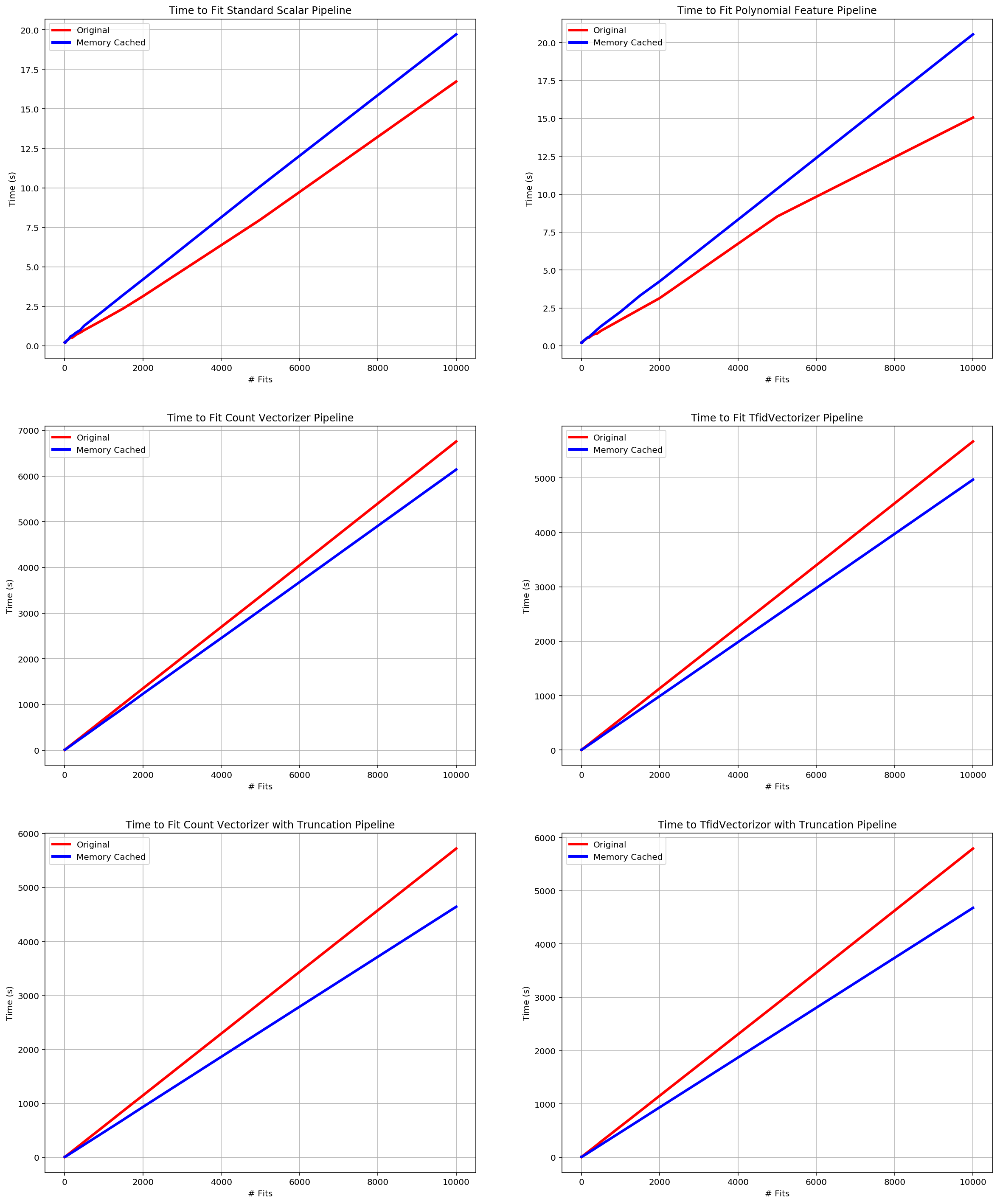
fig = plt.figure(figsize=(20,25))
ax1 = fig.add_subplot(3,2,1)
ax1.plot(eff_orig['fits'], eff_orig['ss_orig'],
lw=3, color='red', label='Original')
ax1.plot(eff_cached['fits'], eff_cached['ss_cached'],
lw=3, color='blue', label='Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Standard Scalar Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax2 = fig.add_subplot(3, 2, 2)
ax2.plot(eff_orig['fits'], eff_orig['pf_orig'],
lw=3, color='red', label='Original')
ax2.plot(eff_cached['fits'], eff_cached['pf_cached'],
lw=3, color='blue', label='Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Polynomial Feature Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax3 = fig.add_subplot(3, 2, 3)
ax3.plot(eff_orig['fits'], eff_orig['cv_orig'],
lw=3, color='red', label='Original')
ax3.plot(eff_cached['fits'], eff_cached['cv_cached'],
lw=3, color='blue', label='Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Count Vectorizer Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax4 = fig.add_subplot(3, 2, 4)
ax4.plot(eff_orig['fits'], eff_orig['tv_orig'],
lw=3, color='red', label='Original')
ax4.plot(eff_cached['fits'], eff_cached['tv_cached'],
lw=3, color='blue', label='Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit TfidVectorizer Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax5 = fig.add_subplot(3, 2, 5)
ax5.plot(eff_orig['fits'], eff_orig['cv_td_orig'],
lw=3, color='red', label='Original')
ax5.plot(eff_cached['fits'], eff_cached['cv_td_cached'],
lw=3, color='blue', label='Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Count Vectorizer with Truncation Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax6 = fig.add_subplot(3, 2, 6)
ax6.plot(eff_orig['fits'], eff_orig['tv_td_orig'],
lw=3, color='red', label='Original')
ax6.plot(eff_cached['fits'], eff_cached['tv_td_cached'],
lw=3, color='blue', label='Memory Cached')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to TfidVectorizor with Truncation Pipeline")
plt.legend(loc = 'best')
plt.grid()
plt.show()
Solving the Issue
import pprint
pp = pprint.PrettyPrinter()
text_pipe = Pipeline([('nlp', CountVectorizer())])
fu = FeatureUnion([
('text', text_pipe),
('text2', text_pipe),
('BLAHBLAH', text_pipe)
])
modeling_pipe = Pipeline([
('data', fu),
('model', LogisticRegression())
])
def logan_search_fit_helper(pipe, params, fset):
pipe.set_params(**params)
scores = []
for k in fset:
#k[0]=Xtr, k[1]=Xte, k[2]=ytr, k[3]=yte
if isinstance(k[0], np.ndarray):
#Is a numpy array
pipe.fit(k[0], k[2])
scores.append(pipe.score(k[1], k[3]))
else:
#Is not Numpy Array
pipe.fit(k[0].copy(), k[2].copy())
scores.append(pipe.score(k[1].copy(), k[3].copy()))
#
return (np.mean(scores), params)
class LoganSearch(BaseSearchCV):
def __init__(self, fu, estimator, param_grid, fu_params={},
n_jobs=1, cv=3, verbose=0):
#set unique attributes
self._fus_ = []
self._base_fu = fu
self._base_fu_params = fu_params
self.cv_ = cv
#set attributes for results
self.best_estimator_ = None
self.best_score_ = None
self.best_params_ = None
#set attributes for GridSearch
self._estimator = estimator
self._param_grid = param_grid
self._n_jobs = n_jobs
self._verbose = verbose
def fit(self, X, y):
self.__set_all_fus(self._base_fu, self._base_fu_params)
folder = check_cv(cv=self.cv_, y=y, classifier=is_classifier(self._estimator))
scores = []
for fu in self._fus_:
fset = []
for tr, te in folder.split(X,y):
Xtmp_tr = fu.fit_transform(X[tr])
Xtmp_te = fu.transform(X[te])
ytmp_tr = y[tr]
ytmp_te = y[te]
fset.append((Xtmp_tr.copy(), Xtmp_te.copy(),
ytmp_tr.copy(), ytmp_te.copy()))
#
print('Done Transforming Data')
print("----------------------------")
n_splits = folder.get_n_splits()
n_candidates = len(ParameterGrid(self._param_grid))
if self._verbose > 0:
print("Fitting {0} folds for each of {1} candidates, totalling"
" {2} fits".format(n_splits, n_candidates,
n_candidates * n_splits))
tmp_results = Parallel(n_jobs=self._n_jobs, verbose=self._verbose
)(delayed(logan_search_fit_helper)
(clone(self._estimator), params, fset)
for params in ParameterGrid(self._param_grid))
scores.extend(tmp_results)
#
#
scores.sort(reverse=True, key=lambda x: x[0])
self.best_score_ = scores[0][0]
self.best_params_ = scores[0][1]
return None
def score(self, X, y):
if not self.best_estimator_:
print('Model must first be fit')
return None
else:
return self.best_estimator_.score(X, y)
def predict(self, X, y):
if not self.best_estimator_:
print('Model must first be fit')
return None
else:
return self.best_estimator_.predict(X, y)
def predict_proba(self, X, y):
if not self.best_estimator_:
print('Model must first be fit')
return None
else:
return self.best_estimator_.predict_proba(X, y)
def __set_all_fus(self, base_fu, fu_params):
tmp_fus = []
for p_name, pipe in base_fu.transformer_list:
tmp_params = sorted([k for k in fu_params.keys() if (k.split("__")[0]==p_name)],
key=lambda x: x.count('__'))
#are there parameters to change for this pipe?
#there are no parameters matching this pipe, so add as is
if not tmp_params:
#list of feature unions is empty
if not tmp_fus:
tmp_fus.append(FeatureUnion([(p_name, pipe)]))
#already feature unions, append to them
else:
for tmp_fu in tmp_fus:
tmp_fu.transformer_list.append((p_name, pipe))
#there are paramters to change
else:
tmp_pipes = [pipe]
if tmp_params[0] == p_name:
tmp_pipes = fu_params[p_name]
# tmp_pipes = [self.add_params(tmp_pipe, {p_name: tmp_pipe})
# for tmp_pipe in fu_params[p_name]]
tmp_params = tmp_params[1:]
#
new_pipes = []
if tmp_params:
for pipe in tmp_pipes:
param_dict = {k:v for k, v in fu_params.items() if k in tmp_params}
for param_comb in ParameterGrid(param_dict):
tmp_pipe = clone(pipe)
#tmp_pipe = self.add_params(tmp_pipe, param_comb)
params_edited = {k.lstrip(p_name+"__"):v for k,v in param_comb.items()}
tmp_pipe.set_params(**params_edited)
new_pipes.append(clone(tmp_pipe))
#
#
else:
new_pipes = tmp_pipes
#add new pipes to feature unions
new_fus = []
#list of feature unions is empty
if not tmp_fus:
for pipe in new_pipes:
new_fu = FeatureUnion([(p_name, pipe)])
new_fus.append(new_fu)
#already feature unions, append to them
else:
for tmp_fu in tmp_fus:
for pipe in new_pipes:
new_fu = clone(tmp_fu)
new_fu.transformer_list.append((p_name, pipe))
new_fus.append(clone(new_fu))
#
tmp_fus = new_fus
#
#
self._fus_ = tmp_fus
return None
def add_params(obj, params):
if hasattr(obj, "params"):
obj.params.update(params)
else:
obj.params = params
return obj
text_pipe = Pipeline([('nlp', CountVectorizer())])
fu = FeatureUnion([
('text', text_pipe),
('text2', text_pipe),
('BLAHBLAH', text_pipe)
])
modeling_pipe = Pipeline([
('data', fu),
('model', LogisticRegression())
])
params = {
'model':[LogisticRegression(penalty='l1'),
LogisticRegression(penalty='l2')]
}
gs = GridSearchCV(modeling_pipe, params, cv=3, n_jobs=-1, verbose=1)
fu_params1 = {
'text__nlp': [CountVectorizer(),
CountVectorizer(ngram_range=(1,2)),
TfidfVectorizer(ngram_range=(1,2)),
TfidfVectorizer()]
}
fu_params2 = {
'text': [Pipeline([('nlp2a', CountVectorizer())]),
Pipeline([('nlp2b', TfidfVectorizer())])
]
}
fu_params3 = {
'text__nlp': [CountVectorizer(),
TfidfVectorizer()],
'text__nlp__ngram_range':[(1,1), (1,2)],
'text2': [Pipeline([('nlp2a', CountVectorizer())]),
Pipeline([('nlp2b', TfidfVectorizer())])
]
}
tfu = FeatureUnion([
('text', StandardScaler())
])
tfpipe = Pipeline([
('model', LogisticRegression())
])
tpipe = Pipeline([
('data', tfu),
('model', LogisticRegression())
])
tparams = {
'model__random_state':range(0,5000)
}
cv = 2
ls = LoganSearch(tfu, tfpipe, tparams, n_jobs=-1, cv=2, verbose=1)
ls.fit(df.nums.values.reshape(-1,1), df.relevance)
pp.pprint((ls.best_score_, ls.best_params_))
gs = GridSearchCV(tpipe, tparams, cv=cv, n_jobs=-1, verbose=1)
gs.fit(df.nums.values.reshape(-1,1), df.relevance)
pp.pprint((gs.best_score_, gs.best_params_))
Fitting 2 folds for each of 5000 candidates, totalling 10000 fits
[Parallel(n_jobs=-1)]: Done 232 tasks | elapsed: 0.6s
[Parallel(n_jobs=-1)]: Done 2032 tasks | elapsed: 3.4s
[Parallel(n_jobs=-1)]: Done 5000 out of 5000 | elapsed: 8.0s finished
(0.82250000000000001, {'model__random_state': 0})
Fitting 2 folds for each of 5000 candidates, totalling 10000 fits
[Parallel(n_jobs=-1)]: Done 268 tasks | elapsed: 0.7s
[Parallel(n_jobs=-1)]: Done 2368 tasks | elapsed: 3.6s
[Parallel(n_jobs=-1)]: Done 5868 tasks | elapsed: 8.5s
(0.82250000000000001, {'model__random_state': 0})
[Parallel(n_jobs=-1)]: Done 10000 out of 10000 | elapsed: 14.0s finished
Run Test with New Function
I will now run the same tests as previously performed, however, I will be using the new LoganSearch class instead of GridSearchCV, and the pipeline will be formatted slightly different to account for that, but will still have the same format.
Reset Params to make it easier to run only parts of the notebook
df = pd.read_csv('sample_data/economic_news.csv', usecols=[7, 11, 14])
df.text = df.text.apply(lambda x: x.replace('</br>', ''))
df.relevance = df.relevance.apply(lambda x: 1 if x == 'yes' else 0)
print(df.shape)
df.head()
(8000, 3)
| relevance | headline | text | |
|---|---|---|---|
| 0 | 1 | Yields on CDs Fell in the Latest Week | NEW YORK -- Yields on most certificates of dep... |
| 1 | 0 | The Morning Brief: White House Seeks to Limit ... | The Wall Street Journal OnlineThe Morning Brie... |
| 2 | 0 | Banking Bill Negotiators Set Compromise --- Pl... | WASHINGTON -- In an effort to achieve banking ... |
| 3 | 0 | Manager's Journal: Sniffing Out Drug Abusers I... | The statistics on the enormous costs of employ... |
| 4 | 1 | Currency Trading: Dollar Remains in Tight Rang... | NEW YORK -- Indecision marked the dollar's ton... |
#set up some stuff
#of times to GridSearch something
reps = [1,5,10,25,50,75,100,150,200,250,500,750,1000,2500,5000]
tmp = []
df['nums'] = df.index
rs = 779
np.random.seed(rs)
df.nums = df.nums.apply(lambda x: 100*x* np.random.rand())
df.head()
| relevance | headline | text | nums | |
|---|---|---|---|---|
| 0 | 1 | Yields on CDs Fell in the Latest Week | NEW YORK -- Yields on most certificates of dep... | 0.000000 |
| 1 | 0 | The Morning Brief: White House Seeks to Limit ... | The Wall Street Journal OnlineThe Morning Brie... | 72.259737 |
| 2 | 0 | Banking Bill Negotiators Set Compromise --- Pl... | WASHINGTON -- In an effort to achieve banking ... | 184.913663 |
| 3 | 0 | Manager's Journal: Sniffing Out Drug Abusers I... | The statistics on the enormous costs of employ... | 94.107106 |
| 4 | 1 | Currency Trading: Dollar Remains in Tight Rang... | NEW YORK -- Indecision marked the dollar's ton... | 336.160412 |
eff_logan = pd.DataFrame(reps, columns=['reps'])
eff_logan['fits'] = eff_logan.reps.apply(lambda x: x*2)
eff_logan
| reps | fits | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 5 | 10 |
| 2 | 10 | 20 |
| 3 | 25 | 50 |
| 4 | 50 | 100 |
| 5 | 75 | 150 |
| 6 | 100 | 200 |
| 7 | 150 | 300 |
| 8 | 200 | 400 |
| 9 | 250 | 500 |
| 10 | 500 | 1000 |
| 11 | 750 | 1500 |
| 12 | 1000 | 2000 |
| 13 | 2500 | 5000 |
| 14 | 5000 | 10000 |
eff_ss = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', StandardScaler())
])
pipe = Pipeline([
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
ls = LoganSearch(fu, pipe, params, n_jobs=-1, cv=2, verbose=1)
#start timer
start = datetime.now()
ls.fit(df.nums.values.reshape(-1,1), df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_ss.append(diff.total_seconds())
eff_logan['ss_logan'] = eff_ss
eff_pf = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', PolynomialFeatures())
])
pipe = Pipeline([
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
ls = LoganSearch(fu, pipe, params, n_jobs=-1, cv=2, verbose=1)
#start timer
start = datetime.now()
ls.fit(df.nums.values.reshape(-1,1), df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_pf.append(diff.total_seconds())
eff_logan['pf_logan'] = eff_pf
eff_cv = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', CountVectorizer())
])
pipe = Pipeline([
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
ls = LoganSearch(fu, pipe, params, n_jobs=-1, cv=2, verbose=1)
#start timer
start = datetime.now()
ls.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_cv.append(diff.total_seconds())
eff_logan['cv_logan'] = eff_cv
Done Transforming Data
----------------------------
Fitting 2 folds for each of 1 candidates, totalling 2 fits
[Parallel(n_jobs=-1)]: Done 1 out of 1 | elapsed: 1.1s finished
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-144-a8aa73131bd1> in <module>()
21 stop = datetime.now()
22 diff = stop - start
---> 23 eff_tv.append(diff.total_seconds())
24
25 eff_logan['cv_logan'] = eff_cv
NameError: name 'eff_tv' is not defined
eff_tv = []
for x in reps:
#setup
fu = FeatureUnion([
('pre-process', TfidfVectorizer())
])
pipe = Pipeline([
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
ls = LoganSearch(fu, pipe, params, n_jobs=-1, cv=2, verbose=1)
#start timer
start = datetime.now()
ls.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_tv.append(diff.total_seconds())
eff_logan['tv_logan'] = eff_tv
eff_cv_td = []
for x in reps:
#setup
fu = FeatureUnion([
('text', Pipeline([
('pre-process', CountVectorizer()),
('truncate', TruncatedSVD(n_components=1, random_state=rs))
]))
])
pipe = Pipeline([
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
ls = LoganSearch(fu, pipe, params, n_jobs=-1, cv=2, verbose=1)
#start timer
start = datetime.now()
ls.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_cv_td.append(diff.total_seconds())
eff_logan['cv_td_logan'] = eff_cv_td
eff_tv_td = []
for x in reps:
#setup
fu = FeatureUnion([
('text', Pipeline([
('pre-process', TfidfVectorizer()),
('truncate', TruncatedSVD(n_components=1, random_state=rs))
]))
])
pipe = Pipeline([
('model', LogisticRegression())
])
params = {
'model__random_state':range(0,x)
}
ls = LoganSearch(fu, pipe, params, n_jobs=-1, cv=2, verbose=1)
#start timer
start = datetime.now()
ls.fit(df.text.values, df.relevance)
#end timer
stop = datetime.now()
diff = stop - start
eff_tv_td.append(diff.total_seconds())
eff_logan['tv_td_logan'] = eff_tv_td
Save to file
eff_logan
| reps | fits | ss_logan | pf_logan | cv_logan | tv_logan | cv_td_logan | tv_td_logan | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 0.223909 | 0.221798 | 6.232115 | 3.607295 | 3.185836 | 3.321109 |
| 1 | 5 | 10 | 0.242797 | 0.226656 | 11.817011 | 3.725415 | 3.517862 | 3.260362 |
| 2 | 10 | 20 | 0.224017 | 0.232498 | 18.046697 | 4.194502 | 3.550491 | 3.297210 |
| 3 | 25 | 50 | 0.331112 | 0.346223 | 39.263028 | 5.359049 | 3.521202 | 3.375086 |
| 4 | 50 | 100 | 0.334166 | 0.456564 | 73.355245 | 7.684017 | 3.552729 | 3.456631 |
| 5 | 75 | 150 | 0.331425 | 0.460818 | 106.176211 | 9.456448 | 3.465066 | 3.469402 |
| 6 | 100 | 200 | 0.433914 | 0.566037 | 139.342304 | 11.695089 | 3.420275 | 3.470165 |
| 7 | 150 | 300 | 0.570316 | 0.570319 | 207.939189 | 15.477273 | 3.633281 | 3.938534 |
| 8 | 200 | 400 | 0.630874 | 0.773557 | 274.387210 | 18.273176 | 3.749651 | 3.728653 |
| 9 | 250 | 500 | 0.757504 | 0.880124 | 341.709382 | 22.261672 | 3.892925 | 3.772603 |
| 10 | 500 | 1000 | 1.172229 | 1.387544 | 678.446888 | 37.435749 | 4.684382 | 4.733261 |
| 11 | 750 | 1500 | 1.525951 | 1.821197 | 1014.473684 | 57.568446 | 4.804530 | 5.297128 |
| 12 | 1000 | 2000 | 1.926059 | 2.506788 | 1352.139445 | 79.162025 | 5.350899 | 5.342550 |
| 13 | 2500 | 5000 | 4.827360 | 5.549650 | 3367.759985 | 186.087186 | 8.388797 | 7.705426 |
| 14 | 5000 | 10000 | 8.561794 | 9.462130 | 6756.219261 | 356.825039 | 14.033000 | 12.286837 |
eff_logan.to_csv('efficiencyDFlogan.csv', index=False)
Visualization and Conclusion
eff_orig = pd.read_csv('efficiencyDForig.csv')
eff_cached = pd.read_csv('efficiencyDFcached.csv')
eff_logan = pd.read_csv('efficiencyDFlogan.csv')
eff_logan
| reps | fits | ss_logan | pf_logan | cv_logan | tv_logan | cv_td_logan | tv_td_logan | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 0.223909 | 0.221798 | 6.232115 | 3.607295 | 3.185836 | 3.321109 |
| 1 | 5 | 10 | 0.242797 | 0.226656 | 11.817011 | 3.725415 | 3.517862 | 3.260362 |
| 2 | 10 | 20 | 0.224017 | 0.232498 | 18.046697 | 4.194502 | 3.550491 | 3.297210 |
| 3 | 25 | 50 | 0.331112 | 0.346223 | 39.263028 | 5.359049 | 3.521202 | 3.375086 |
| 4 | 50 | 100 | 0.334166 | 0.456564 | 73.355245 | 7.684017 | 3.552729 | 3.456631 |
| 5 | 75 | 150 | 0.331425 | 0.460818 | 106.176211 | 9.456448 | 3.465066 | 3.469402 |
| 6 | 100 | 200 | 0.433914 | 0.566037 | 139.342304 | 11.695089 | 3.420275 | 3.470165 |
| 7 | 150 | 300 | 0.570316 | 0.570319 | 207.939189 | 15.477273 | 3.633281 | 3.938534 |
| 8 | 200 | 400 | 0.630874 | 0.773557 | 274.387210 | 18.273176 | 3.749651 | 3.728653 |
| 9 | 250 | 500 | 0.757504 | 0.880124 | 341.709382 | 22.261672 | 3.892925 | 3.772603 |
| 10 | 500 | 1000 | 1.172229 | 1.387544 | 678.446888 | 37.435749 | 4.684382 | 4.733261 |
| 11 | 750 | 1500 | 1.525951 | 1.821197 | 1014.473684 | 57.568446 | 4.804530 | 5.297128 |
| 12 | 1000 | 2000 | 1.926059 | 2.506788 | 1352.139445 | 79.162025 | 5.350899 | 5.342550 |
| 13 | 2500 | 5000 | 4.827360 | 5.549650 | 3367.759985 | 186.087186 | 8.388797 | 7.705426 |
| 14 | 5000 | 10000 | 8.561794 | 9.462130 | 6756.219261 | 356.825039 | 14.033000 | 12.286837 |
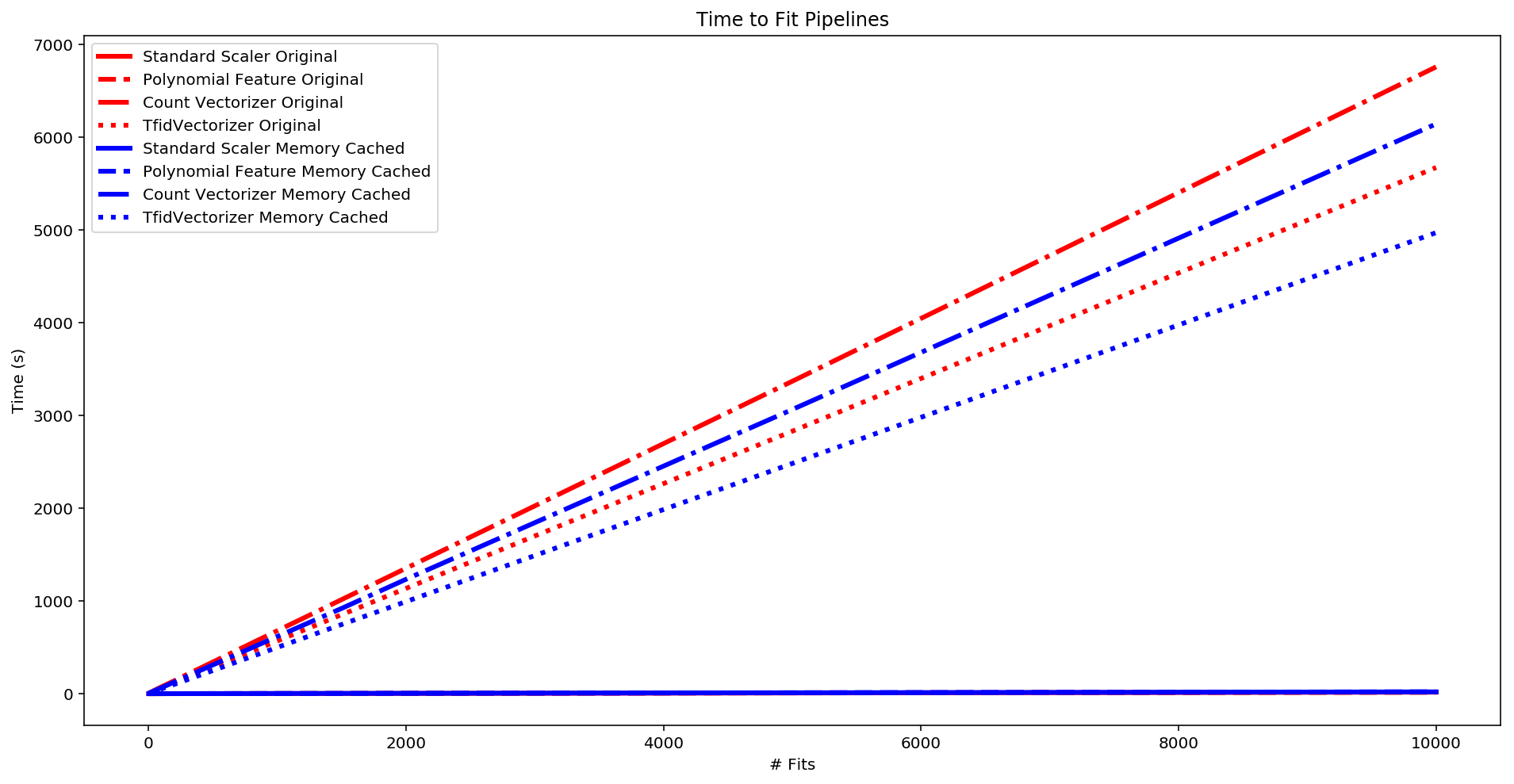
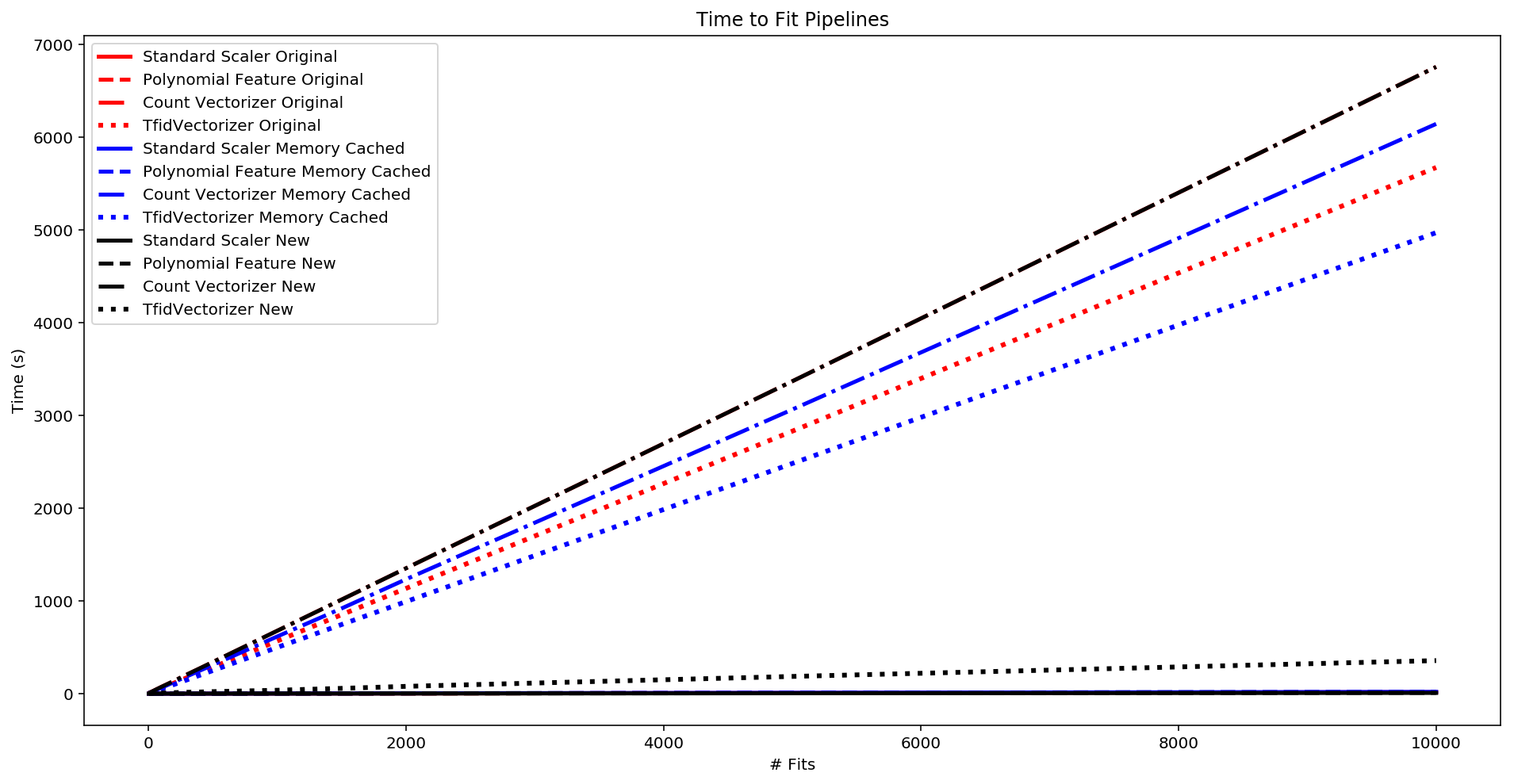
fig, ax = plt.subplots(figsize=(16,8))
plt.plot(eff_orig['fits'], eff_orig['ss_orig'],
lw=2.5, color='red', label='Standard Scaler Original')
plt.plot(eff_orig['fits'], eff_orig['pf_orig'],
lw=2.5, color='red', linestyle='--', label='Polynomial Feature Original')
plt.plot(eff_orig['fits'], eff_orig['cv_orig'],
lw=2.5, color='red', linestyle='-.', label='Count Vectorizer Original')
plt.plot(eff_orig['fits'], eff_orig['tv_orig'],
lw=3, color='red', linestyle=':', label='TfidVectorizer Original')
plt.plot(eff_cached['fits'], eff_cached['ss_cached'],
lw=2.5, color='blue', label='Standard Scaler Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['pf_cached'],
lw=2.5, color='blue', linestyle='--', label='Polynomial Feature Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['cv_cached'],
lw=2.5, color='blue', linestyle='-.', label='Count Vectorizer Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['tv_cached'],
lw=3, color='blue', linestyle=':', label='TfidVectorizer Memory Cached')
plt.plot(eff_logan['fits'], eff_logan['ss_logan'],
lw=2.5, color='black', label='Standard Scaler New')
plt.plot(eff_logan['fits'], eff_logan['pf_logan'],
lw=2.5, color='black', linestyle='--', label='Polynomial Feature New')
plt.plot(eff_logan['fits'], eff_logan['cv_logan'],
lw=2.5, color='black', linestyle='-.', label='Count Vectorizer New')
plt.plot(eff_logan['fits'], eff_logan['tv_logan'],
lw=3, color='black', linestyle=':', label='TfidVectorizer New')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Pipelines")
plt.legend(loc = 'best')
plt.show()
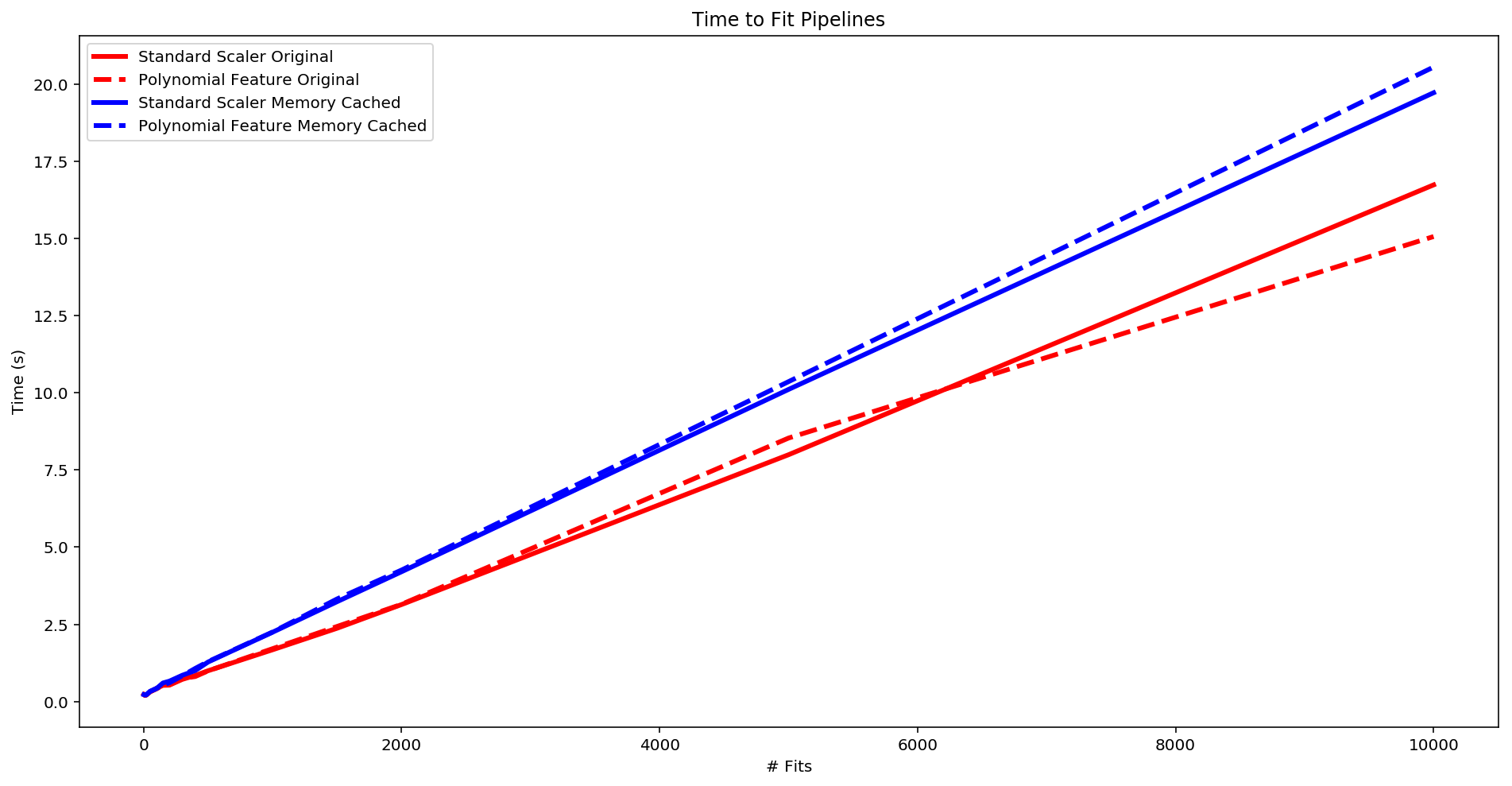
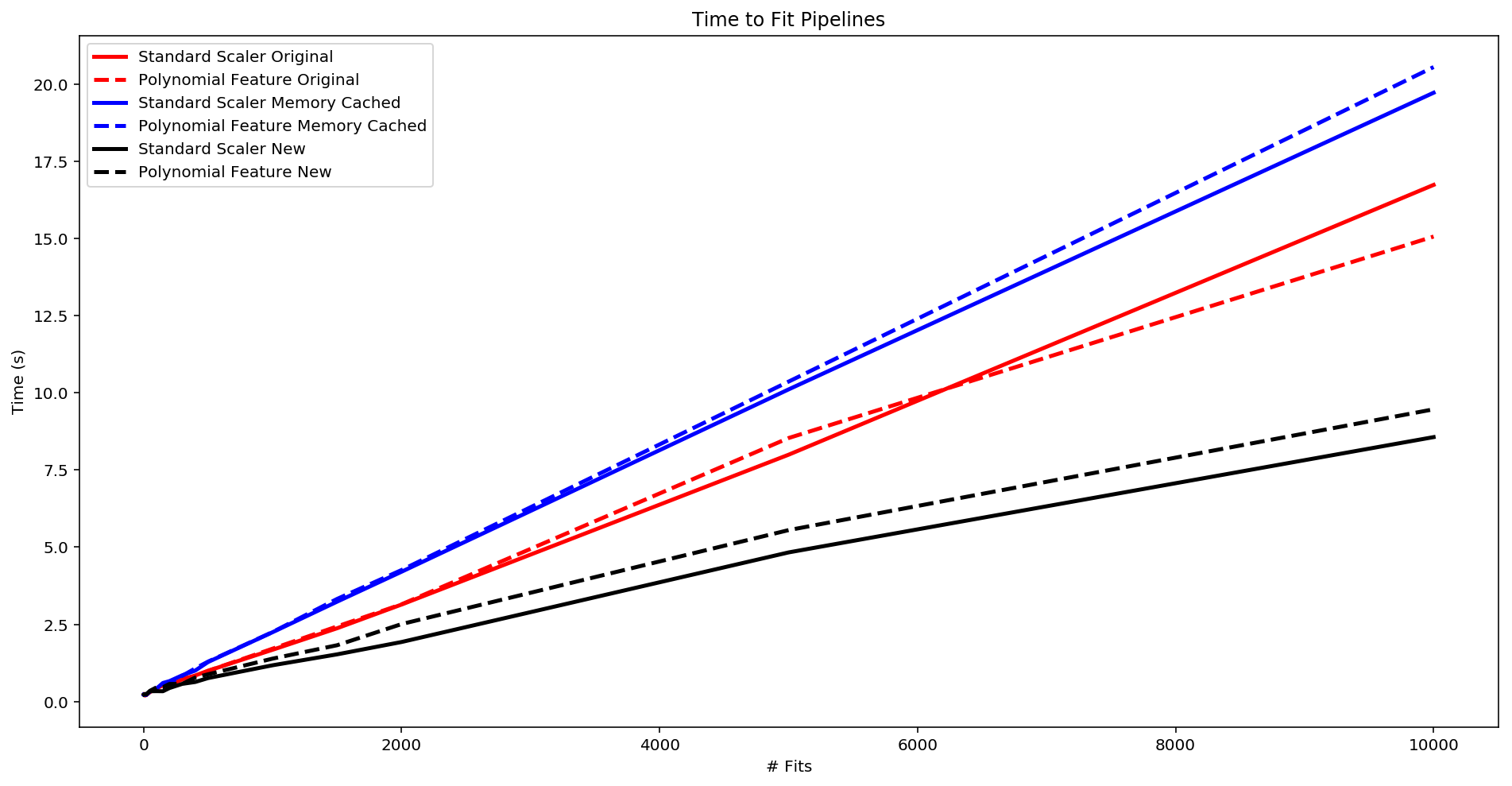
fig, ax = plt.subplots(figsize=(16,8))
plt.plot(eff_orig['fits'], eff_orig['ss_orig'],
lw=2.5, color='red', label='Standard Scaler Original')
plt.plot(eff_orig['fits'], eff_orig['pf_orig'],
lw=2.5, color='red', linestyle='--', label='Polynomial Feature Original')
plt.plot(eff_cached['fits'], eff_cached['ss_cached'],
lw=2.5, color='blue', label='Standard Scaler Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['pf_cached'],
lw=2.5, color='blue', linestyle='--', label='Polynomial Feature Memory Cached')
plt.plot(eff_logan['fits'], eff_logan['ss_logan'],
lw=2.5, color='black', label='Standard Scaler New')
plt.plot(eff_logan['fits'], eff_logan['pf_logan'],
lw=2.5, color='black', linestyle='--', label='Polynomial Feature New')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Pipelines")
plt.legend(loc = 'best')
plt.show()
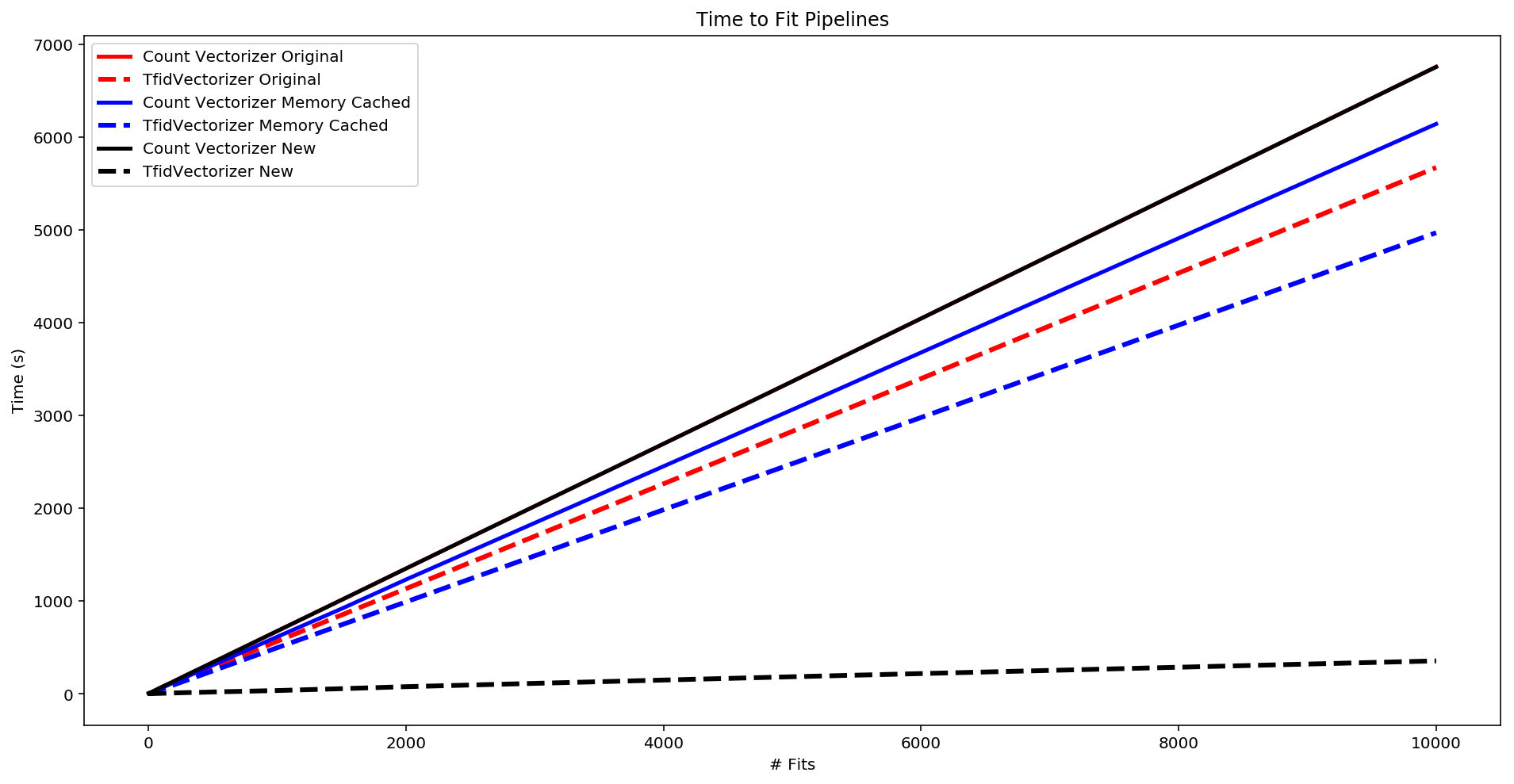
fig, ax = plt.subplots(figsize=(16,8))
plt.plot(eff_orig['fits'], eff_orig['cv_orig'],
lw=2.5, color='red', linestyle='-', label='Count Vectorizer Original')
plt.plot(eff_orig['fits'], eff_orig['tv_orig'],
lw=3, color='red', linestyle='--', label='TfidVectorizer Original')
plt.plot(eff_cached['fits'], eff_cached['cv_cached'],
lw=2.5, color='blue', linestyle='-', label='Count Vectorizer Memory Cached')
plt.plot(eff_cached['fits'], eff_cached['tv_cached'],
lw=3, color='blue', linestyle='--', label='TfidVectorizer Memory Cached')
plt.plot(eff_logan['fits'], eff_logan['cv_logan'],
lw=2.5, color='black', linestyle='-', label='Count Vectorizer New')
plt.plot(eff_logan['fits'], eff_logan['tv_logan'],
lw=3, color='black', linestyle='--', label='TfidVectorizer New')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Pipelines")
plt.legend(loc = 'best')
plt.show()
Visualization by Pipline
eff_logan
| reps | fits | ss_logan | pf_logan | cv_logan | tv_logan | cv_td_logan | tv_td_logan | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 0.337648 | 0.329182 | 4.815905 | 2.197995 | 2.043521 | 2.265842 |
| 1 | 5 | 10 | 0.336465 | 0.344149 | 6.568332 | 2.512184 | 2.158687 | 2.040282 |
| 2 | 10 | 20 | 0.341959 | 0.336109 | 8.806089 | 2.928364 | 2.333201 | 2.061443 |
| 3 | 25 | 50 | 0.437900 | 0.423550 | 16.460682 | 4.176842 | 2.383285 | 2.382574 |
| 4 | 50 | 100 | 0.434349 | 0.542314 | 28.065589 | 6.179202 | 2.338781 | 2.343176 |
| 5 | 75 | 150 | 0.562190 | 0.641041 | 40.617662 | 8.128802 | 2.553450 | 2.371559 |
| 6 | 100 | 200 | 0.619316 | 0.646805 | 50.271060 | 10.255086 | 2.554965 | 2.452167 |
| 7 | 150 | 300 | 0.785087 | 0.839261 | 71.012454 | 14.410503 | 2.780835 | 2.431730 |
| 8 | 200 | 400 | 0.887184 | 0.883647 | 90.469659 | 18.092645 | 2.831297 | 2.582043 |
| 9 | 250 | 500 | 1.088669 | 1.099337 | 110.879169 | 22.177632 | 2.991412 | 2.716854 |
| 10 | 500 | 1000 | 1.838825 | 1.630478 | 226.336279 | 42.359731 | 4.005885 | 3.290292 |
| 11 | 750 | 1500 | 2.096881 | 2.278316 | 334.308263 | 62.534262 | 4.399962 | 3.818105 |
| 12 | 1000 | 2000 | 2.996025 | 2.956987 | 453.728119 | 82.371572 | 5.327830 | 4.707286 |
| 13 | 2500 | 5000 | 5.997752 | 6.383000 | 1120.259022 | 202.750489 | 9.461915 | 7.908639 |
| 14 | 5000 | 10000 | 11.603223 | 13.809455 | 2160.935821 | 406.772957 | 16.150460 | 13.800006 |
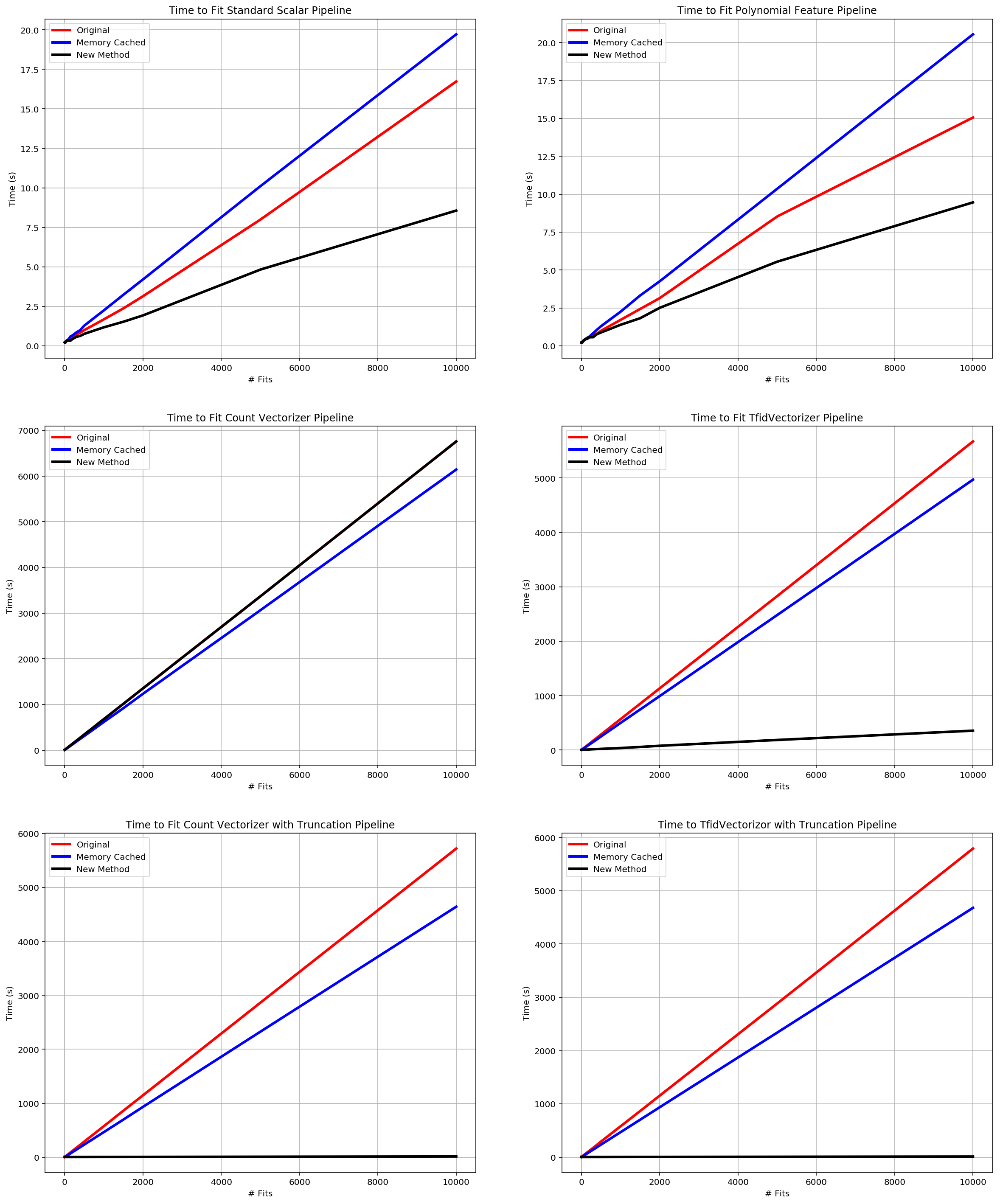
fig = plt.figure(figsize=(20,25))
ax1 = fig.add_subplot(3,2,1)
ax1.plot(eff_orig['fits'], eff_orig['ss_orig'],
lw=3, color='red', label='Original')
ax1.plot(eff_cached['fits'], eff_cached['ss_cached'],
lw=3, color='blue', label='Memory Cached')
ax1.plot(eff_logan['fits'], eff_logan['ss_logan'],
lw=3, color='black', label='New Method')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Standard Scalar Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax2 = fig.add_subplot(3, 2, 2)
ax2.plot(eff_orig['fits'], eff_orig['pf_orig'],
lw=3, color='red', label='Original')
ax2.plot(eff_cached['fits'], eff_cached['pf_cached'],
lw=3, color='blue', label='Memory Cached')
ax2.plot(eff_logan['fits'], eff_logan['pf_logan'],
lw=3, color='black', label='New Method')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Polynomial Feature Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax3 = fig.add_subplot(3, 2, 3)
ax3.plot(eff_orig['fits'], eff_orig['cv_orig'],
lw=3, color='red', label='Original')
ax3.plot(eff_cached['fits'], eff_cached['cv_cached'],
lw=3, color='blue', label='Memory Cached')
ax3.plot(eff_logan['fits'], eff_logan['cv_logan'],
lw=3, color='black', label='New Method')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Count Vectorizer Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax4 = fig.add_subplot(3, 2, 4)
ax4.plot(eff_orig['fits'], eff_orig['tv_orig'],
lw=3, color='red', label='Original')
ax4.plot(eff_cached['fits'], eff_cached['tv_cached'],
lw=3, color='blue', label='Memory Cached')
ax4.plot(eff_logan['fits'], eff_logan['tv_logan'],
lw=3, color='black', label='New Method')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit TfidVectorizer Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax5 = fig.add_subplot(3, 2, 5)
ax5.plot(eff_orig['fits'], eff_orig['cv_td_orig'],
lw=3, color='red', label='Original')
ax5.plot(eff_cached['fits'], eff_cached['cv_td_cached'],
lw=3, color='blue', label='Memory Cached')
ax5.plot(eff_logan['fits'], eff_logan['cv_td_logan'],
lw=3, color='black', label='New Method')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to Fit Count Vectorizer with Truncation Pipeline")
plt.legend(loc = 'best')
plt.grid()
ax6 = fig.add_subplot(3, 2, 6)
ax6.plot(eff_orig['fits'], eff_orig['tv_td_orig'],
lw=3, color='red', label='Original')
ax6.plot(eff_cached['fits'], eff_cached['tv_td_cached'],
lw=3, color='blue', label='Memory Cached')
ax6.plot(eff_logan['fits'], eff_logan['tv_td_logan'],
lw=3, color='black', label='New Method')
plt.xlabel('# Fits')
plt.ylabel('Time (s)')
plt.title("Time to TfidVectorizor with Truncation Pipeline")
plt.legend(loc = 'best')
plt.grid()
plt.show()